by Kade Hansson
Mr Architecture is a component architecture based on EJB 2.1. Its hallmark properties are:
Mr Architecture takes the best of EJB 2.1 and shoehorns it into a framework which allows the rapid deployment of efficient, reliable and scalable applications.
In order to configure and deploy applications using Mr Architecture most effectively, you will need to have some knowledge of its caching apparatus and its ability for multithreading. However, application and bean developers do not need to know all these details to write applications, but some guidelines are pertinent:
The best way to run a Mr Architecture application is in the way it was originally intended: many performant client machines running ClientContainers on separate Java virtual machines (VMs,) connected to a single, fully-cached ServerContainer on a performant server machine (also with a VM.) By performant, we mean the machine should be powerful to enough to handle its assigned workload by providing:
Unfortunately, exactly what this means in terms of specific hardware requirements such as choice of operating system (OS,) virtual machine, garbage collection strategy, processor type, number of processors or cores, application space allocation, process priority, amount of swap space and RAM will need to be determined through profiling each application. However, this document will hopefully give some insight into how Mr Architecture may be placing demands on client and server infrastructure.
While the client-server arrangement is recommended, Mr Architecture is flexible enough to run in a server-only mode for pure web applications (such as those which take advantage of the Ms Architecture Extension's UIServlet,) however in this case you will need a server machine which is proportionally more performant, as it will be doing some of the work which was previously limited to client VMs.
A Java application, just like any other application on a system, needs enough memory to do the work it has been assigned. The memory assigned to a Java application by the operating system is primarily for the Java heap, which contains Java objects (mostly,) and is managed by the garbage collector of the chosen virtual machine. If the allocated heap is not big enough to hold all of the objects for all of the running threads, it will need to grow. If you do not allow the heap to grow, your application will not necessarily fail immediately, but will instead try to recover by searching (aimlessly in this case) for blocks to free. When a thread fails to allocate a block, it dies, and so free blocks arise from the partial work it accomplished. Something else then attempts to run, or the aborted operation is retried: this too fails, because the system still doesn't have the memory it needs.
In a compiled program which allocates its own blocks (probably with the assistance of a heap management library,) situations like that described above are fatal conditions, and the application will fail immediately: this is because there is no garbage collector to attempt a recovery of the situation. Such faults are detected and repaired quickly, because otherwise the system would fail constantly, destroying all users' ability to do any work at regular intervals.
However, a Java application starved of memory will compensate, by way of the garbage collector, by consuming processor, another limited resource. This will not only make the application fail intermittently, and work much more slowly, it will actually affect all other processes in the server machine! The result is instead that most users' ability to do much work is impaired until the process is terminated (which only then destroys users' ability to do work.)
It is imperative, therefore, that the Java heap be allowed to grow to whatever is necessary to run the application at hand. This is difficult to estimate, although we will now attempt to do this for Mr Architecture in a qualitative, if not quantitative, way. The primary user of memory within the VM of a Mr Architecture application are the LRU caches, but these alone cannot ever result in exhaustion of memory, as will also be explained. Therefore if an application runs out of memory, and begins to saturate the processor, it is simply because there is not enough space available for that application to process all the objects it needs to perform any given task. This may be because of application error, but it is also possible that the tasks running are demanding enough to need a lot of memory.
The most important divsion of the caches into Mr Architecture is between client and server. All standard EJB implementation have a single ServerContainer even if this is hosted on multiple cooperating machines. Therefore these implementations only have one cache, though this may be conceptually treated as many caches, one for each bean type (see below) for the purposes of analysis. However, in Mr Architecture, where there are typically many ClientContainers in addition to that on the server, there are caches not only in the server, but also on every client.
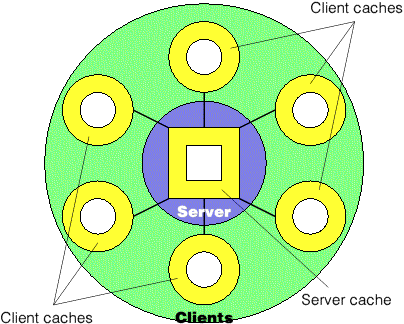
When a data record is in a client cache (whose contents arise from the recent transactions of the local user only,) there is no need for that client to even connect to the server to obtain that data. When a record is not in the client cache, the server is contacted. The server may then use its cache (whose contents are determined by the recent transactions of all users) to fulfil a request for a object representations of data records and record sets without reconstituting it using database queries.
In order to prevent the client caches from becoming stale, there is some feedback from the server indicating which beans have recently changed. As soon as a notification is received which identifies a bean currently in the client cache, it is discarded so long as it is also unmodified in that client. (This latter constraint prevents data which the user is currently editing from being lost- but neither will it be allowed to return to the server without some kind of merge action being undertaken outside the architecture.)
Because of the way these messages are limited in size and piggybacked on the end of responses to other transactions, there is a danger, during a period of high activity on the server, or during a period of low activity on the client, that some notifications will be lost. Currently, as of version 3.0, the architecture has no way of signalling such a condition, so in these situations clients may rely on out-of-synch data. The only protection arises because this data will not be permitted to pollute more up-to-date data on the server if the user tries to commit it to persistent storage. Also, because the signalling mechanism can potentially require a lot of information to be communicated during periods of high activity on the server, transactions executed during these periods will be proportionately larger, and thus slower to generate, transport and digest. In general, the architecture seeks to limit this overhead to 64 kB (or about 5 ms at 100 Mb s-1) per transaction.
Mr Architecture, like all EJB containers, divides entity beans into homes, where all beans derived by the same abstract bean class template are grouped together. While homes provide an API which allows beans to be created and selected from persistent storage, conceptually they also provide a place where beans live. It is a natural extension, therefore, to imagine that each home has an associated cache of recently accessed beans.
A complication arises because of the way Mr Architecture chooses to implement client-server bean migration--a concept unique to Mr Architecture. This results in beans existing in two implementation forms--one which can be physically transported, and one which can have its encapsulated data atomically replaced by such a transported bean. The form of bean which is physically transported is a called "thin" entity bean (or just thin bean,) and the form of bean which can have its encapsulated data atomically replaced is called a Mr Bean, or bean object. This implementation detail is fairly well hidden from clients of Mr Architecture, who only see thin beans used as tokens to convey bean type information, but it is important to the caching structure adopted by Mr Architecture.
Each home, instead of having one cache of beans, has two caches--one for each of the implementation forms in Mr Architecture. Bean objects are cached to attempt to ensure that two requests for the same bean will result in the same Mr Bean reference being returned. Mr Architecture does not guarantee this to be the case, but it is still of advantage not to create multiple views of data if possible, if only to minimize wasted space. Thin beans are cached for this reason and also to encourage data to "fade" from the cache and not disappear suddenly (see the implementation notes further below.) Further to these justifications, thin beans must be cached in the server if any benefit is to be obtained- most of the data in the server never develops into Mr Beans, as these are not required in the transport layer.
Another type of cache is only used in the server. The response cache keeps the responses to recently executed commands, and commonly contains the results of bulk lookup data queries, such as those used to populate menus and drop-down lists. A request which can be served by the response case is much faster than any request which needs to query the database, even if the database itself performs caching, because of the JDBC connection overhead and the overhead in producing object representations for transport. Therefore, the response cache also mitigates the performance cost of inefficient code which does redundant data accesses.
It is not Mr Architecture's aim to cache all frequently-used data using complex heuristics. Instead Mr Architecture aims to have the as much of the most frequently-requested unchanging data available as is possible without the need for much developer foresight or intervention. Mr Architecture would rather have a small memory footprint than a cache which delivers maximal performance under actual load conditions.
Put more succinctly, as soon as a data record in any home changes, all records belonging to that home are immediately dumped from all server caches. (The client caches are more forgiving.) This keeps the histogram of cache contents strongly biased towards those homes whose records and record sets that are not changing. Primarily data in the server cache will be look-up data, which is very commonly requested by clients, but changes relatively infrequently. Data which is immediately excluded from server caches under this strategy, without the need for programmer configuration, are frequently changing homes, such as those used for bean trails, audit trails and activity logging.
There are, naturally, circumstances in which the caching strategy fails to deliver perfomance gains, and may actually have a detrimental effect on performance. The best example is a home which remains largely static, but is extremely large, and the set of records requested is diverse. To avoid flooding the cache with the records from such homes for no performance benefit and a high space overhead, Mr Architecture gives the option to manually exclude particular homes from caches on either the client or server or both. The default behaviour, however, is to automatically cache all homes in both the client and server, and in most applications this gives a modest performance improvement while retaining a small memory footprint.
In circumstances where a small memory footprint is strongly desired, it is recommended that the Java virtual machine memory be limited and not be allowed to grow. This will result in a not insignificant performance degradation, as the garbage collector in the virtual machine will have to work harder to ensure memory is available. So, be aware that you may be shooting yourself in the foot.
The diagram below is an approximation of the typical memory layout of the Java VM and Mr Architecture server heap. It does not indicate that the various elements of the Mr Architecture server heap are fragmented across the entire heap space, and it is not detailed enough to do justice to the full range of possibilities of VM, OS and memory configurations. For example, some VM and OS combinations may load dynamically linked library images above the VM image, possibly sharing them with other processes if the processor and OS combination supports doubly-mapped virtual addressing schemes. Also, while the diagram shows per thread overhead in the heap, this may be internal or external to the virtual machine depending on what type of threading library the VM is using and how the OS supports that library. Some VMs may even implement threads within the VM process without the need for library or OS support.
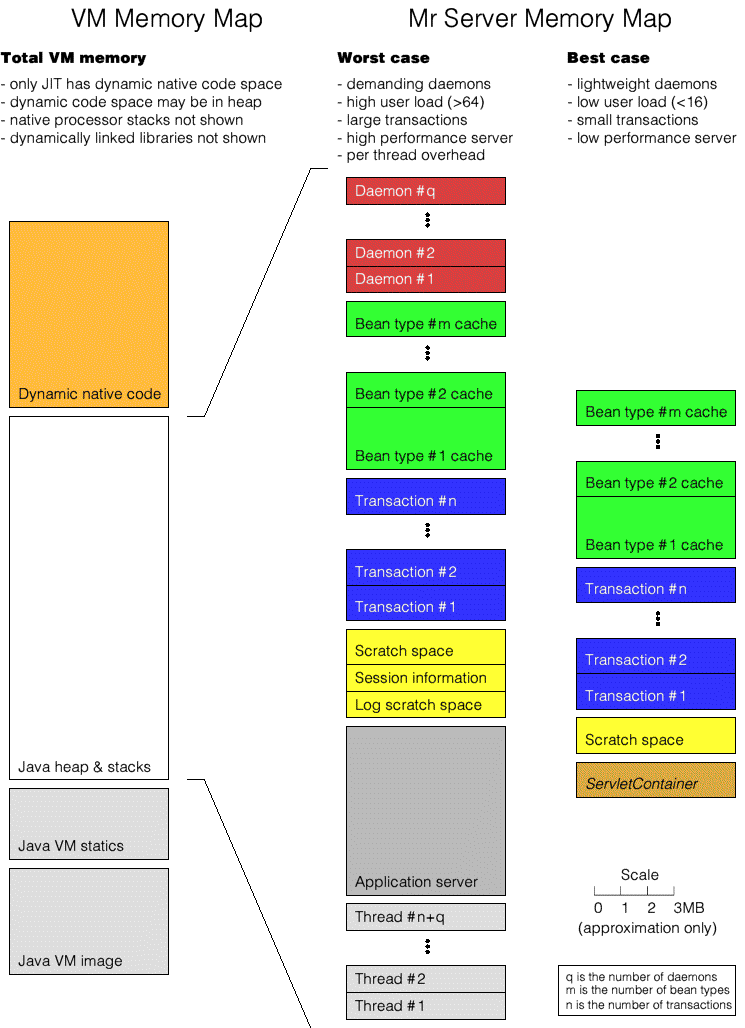
As per the diagram, the size of the minimal heap footprint one can safely choose in a purely interpreted VM[1] is roughly equivalent to the total of the memory requirement of the supporting application server (where one is used,) the size of all the classes constituting the application (not shown), a 1 MB allocation of scratch space, the size of the maximal expected transaction[2] (as serialized) multiplied by the expected worst case concurrent user count[3], plus the desired space to be reserved to hold cached results (where sizes can be estimated based on a histogram analysis of the cache per bean type composition and knowledge of the size of the serialized packets involved in transporting each cache element.) Applications which use daemons will also have to consider the memory requirements of their daemons, and beans which use the invokeOnServer() facility will also have to be taken into account where these can impose a significant memory requirement (say greater than 500 kB.)
As we've mentioned in passing, Java's memory management involves the use of a garbage collector in order to reclaim unreachable objects from the heap. Unreachable objects are those not reachable by a strong reference--that is any ordinary object reference. Java does not define when the garbage collector runs, or which objects must be garbage collected, only what reachable and unreachable objects are. A typical garbage collector will remove some of the unreachable objects each time it runs, but it may also spend a fair proportion of its time doing other housekeeping, such as traversing the object graph to determine which objects have become unreachable.
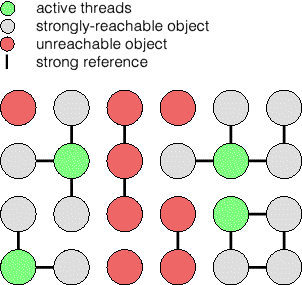
Besides a strong reference, Java additionally implements the concept of a SoftReference, which is a reference which is only garbage collected when memory is tight. Such references can be used to implement memory-dependent caches, and they are used for this purpose in Mr Architecture. An object which is only reachable by a SoftReference is said to be softly-reachable. When the garbage collector determines that more free memory is needed, and all the strongly and weakly unreachable objects have been garbage collected, it may begin to garbage collect these softly reachable objects.
Java implementations should garbage collect those softly reachable objects least recently used (LRU) first, but no requirement is imposed. In practice, however, most virtual machines (such as HotSpot) do a good job at implementing a LRU cache when using SoftReferences.
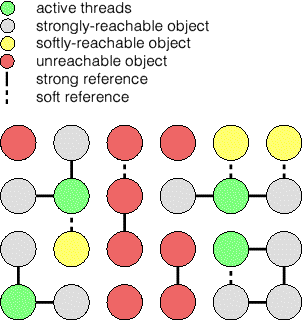
Because a newly included softly reachable object is more recently used than any other softly reachable object in the cache, the cache keeps more recently accessed information. When memory is tight, the inclusion of a new softly reachable object in memory may cause one of the LRU sofly reachable objects to be garbage collected--and so the cache evolves to include more recent references over time. If an object is already in a softly reachable cache, the action of retrieving it reinforces its place in that cache. Therefore objects which are commonly accessed are much more likely to be in the cache than those which which are accessed only sporadically.
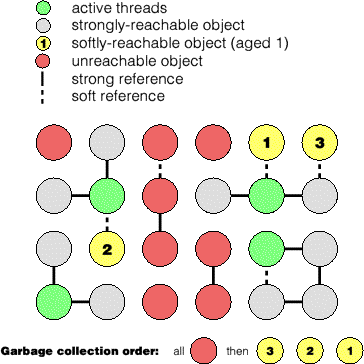
In order to prevent clients from keeping data for too long, and perhaps missing a change to that data on the server, Mr Architecture extends the concept of a SoftReference to a TimedReference. A TimedReference is a SoftReference which eventually becomes stale and is removed from the cache even if it is frequently accessed. TimedReferences also reinforce Mr Architecture's design goal of caching as little as possible in order to maintain a small memory footprint--thanks to TimedReferences all Mr Architecture caches decay over time, even if there is no low-memory condition or other imperative for them to do so. For example, a Mr Architecture cache left overnight with no throughput will be empty before the first transaction of the morning.
Besides individual cache attrition and decay, collectively the Mr Architecture caches also experience fade. Because the Mr Architecture server has three levels of cache, and the client has two, where each level contains objects which strongly reference objects in the next level down, low level objects (i.e. beans or bean objects) take longer to disappear than might otherwise be the case. For example, if a bean is part of a response, just because that response has been removed from the response cache does not mean the bean is removed from the bean cache. If a request comes in after its matching response has been removed, it may still be possible to relatively rapidly reconstruct it from the bean cache-- resurrecting the response in the response cache in the process. This resurrection behaviour can significantly improve the cache utilization, and comes with little cost, being a side-effect of the tiered cache approach.
A remote interaction occurs as the result of any life-cycle or finder method call on the client, with the exception of createImmediately(). All such method calls have the potential to result in commands being sent to the server, and a corresponding response being received. The timing of such requests and responses depends on the transaction state and also the transactional behaviour of each command (for example, finder methods do not participate in transactions).
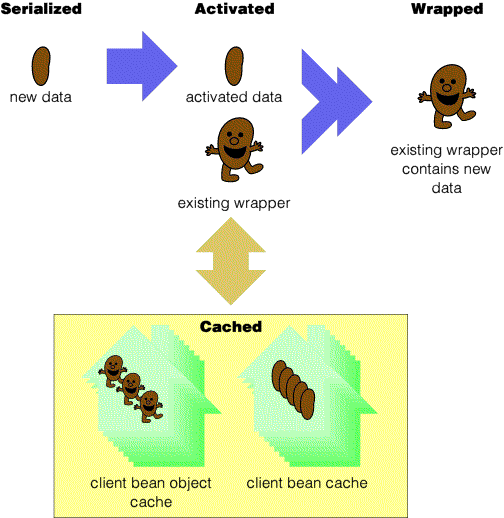
As a bean enters the client from the server, it is activated and wrapped. Wrapping will not involve the cache where the bean is returing from a round trip to the server, as occurs during the execution of a load, store or remove command. In these instances, the wrapper which invoked the command will accept the new entity bean (or changed part thereof.)
Part of activation ensures that the entity bean is recorded in a client cache storing such entity beans. Where the entity bean is not returning from a round trip, a corresponding wrapper needs to be found. This wrapper may be obtained from another client cache containing such wrappers, provided the wrapper in that cache has not been dirtied. Otherwise, a fresh wrapper is created, which may replace the other wrapper in the cache on a subsequent remote interaction.
Bean wrappers in the client cache which are not dirty are subject to change between server interactions. For example, if you are holding a reference to a non-dirty bean object which is subsequently returned as the result of a siamese bean or finder query, its data may be refreshed. This is particularly relevant where the client needs to be multithreaded, because in order to ensure data is modified atomically you will need to either synchronize method accesses--add the methods lock() and release() to your beans to ensure that the architecture enforces mutual exclusion--or make copies of beans using deeperClone() before altering any state.
Subsequent requests for the entity bean or its wrapper will be served locally by the contents of these client caches, except when that bean is the result of a select or join command--in such cases only the wrapper will be obtained from the cache (assuming that wrapper has not been dirtied.)
Invoke commands use call-by-value semantics, and additionally any beans contained in the result are cloned so that they will not affect the cache unless subsequently stored or reloaded. However, if the server stored any of the beans it returned, these may be removed from caches by the action of a third party interaction notification (where the server is both the second and third party.)
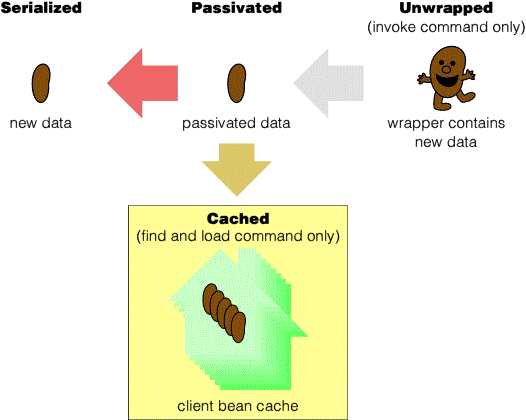
As a bean exits the client on its way to the server, it is unwrapped and passivated. This has no effect on the cache, except that all beans on a round trip to the server will be in a passivated state.

A remote interaction is a batch of commands or a transaction sent from a client to be executed by the server. It involves the sending of either a string of responses corresponding to each command in the batch or transaction on a one-to-one basis, or an exception. It is valid for one command (in particular the echo command) to have more than one response or no response (the begin command,) but the one-to-one case is much more usual. A third party interaction notification is sent in the form of a response appended to the end of the collection after all other responses.
As a bean enters the server from a client, it is activated. Part of the activation process ensures that any cached copy of the entity bean itself or corresponding wrapper is removed from the server caches. This ensures that where data in the bean is committed to the database (or not,) the next request for the bean will produce a fresh copy of the bean from the database.
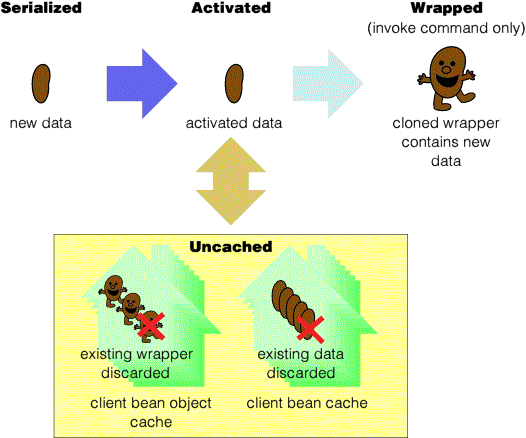
Only a find command (generated in response to a findByPrimaryKey() method call in the ClientContainer) or a load command (generated in response to a load() method call on a bean object) will update an entity bean in the server cache. A select or join (generated in response to all other queries) has no effect on the server cache (excluding the remote interaction cache, or response cache-- see below). None of these commands can occur in a transaction with other commands, so transaction states can be ignored--these operations are always atomic. (If this were not the case, the cache effect would have to occur in synchrony[4] with the data commission.)
The caching action allows subsequent find or load commands referencing the same bean to be served without reference to the database.
Upon successful commission of a transaction involving store and remove commands, the caches are flushed so that they no longer contain any references to beans of the types committed in that transaction. This ensures integrity of the cache where a find or load command for a bean (necessarily in a third party transaction) executed during the course of a transaction involving that bean. (If the reference were removed only at the beginning of the transaction or during the course of a transaction, there is a danger of a race condition when an intervening find or load command puts the reference back.)
As a bean exits the server on its way from a client, it is passivated. This has no effect on the cache, except that all beans which are not in use on the server will be in a passivated state.
In addition to caching of beans, the server caches some interactions, so that the execution of two identical find or select commands without any intervening store, remove or flush commands involving the same bean type can (for the second and subsequent commands) produce an identical response immediately. The cache involved is called the response cache.
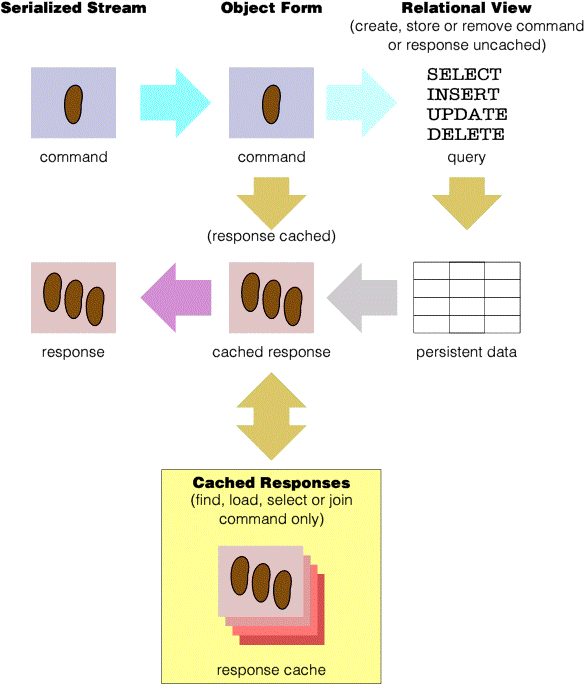
The client is the first party. The server is the second party. In some cases, a third party, typically another client, although it may also be the first or second party, may cause the cache to change. Where a third party changes a bean, the action of the second party is to do all that is reasonably possible to notify the first party that such a change has occurred. The server achieves this by maintaining a queue of bean identifiers which are passed to the client as part of each interaction. These identifiers represent the beans which third parties have affected since the last interaction between the first and second party. The first party removes all references to such beans from their local caches so that subsequent accesses will cause fresh data to be obtained from the second party.
As has been previously noted, this notification system may cause a slow down during bulk updates of data, and to cap this slow down at reasonable levels, the queue is only allowed to grow to a length of five hundred or so bean identifiers. Less recent updates are expunged from the queue in such situations.
A local interaction occurs as the result of any life-cycle method call which does not interact with the server at any time. Only createImmediately() methods execute without any such remote interaction, and these never involve the cache.
A local interaction is where the server asks itself to perform an operation internally.
During local interactions, bean wrappers corresponding to entity beans are placed in the server cache. Local interactions include those which occur through the action of findAll...() methods, invokeOnServer() methods and ServerDaemons. Parameters to invokeOnServer() are cloned, and are independent of the cache unless explicitly stored by action of the method.
Bean wrappers which have not been dirtied and are not clones are subject to change by client interactions (and local interactions in other server threads,) just as such bean wrappers in the client can be affected by server interactions (and local interactions in other client threads.) The server is neccessarily multithreaded, so it is important to either synchronize method accesses--add the methods lock() and release() to your beans to ensure that the architecture enforces mutual exclusion--or make copies of beans using deeperClone() before altering any state.
The converse is also true--client interactions may be affected if you are working on cached objects. During a local interaction, should an invokeOnServer() method or ServerDaemon modify a bean, it will immediately affect the cache even if a transaction is being managed by the calling thread. This behaviour is normally undesirable, so before modifying beans returned from finder or siamese bean queries, remember to clone them using the deeperClone() method. The same situation will arise when the cloned bean is stored (and subsequent to the transaction, if one is being managed, committed) and then modified. Committing beans during an invokeOnServer() method or ServerDaemon worker thread has the effect of "uncloning" them.
Local server transactions also take advantage of the response cache. See the previous section under remote interaction caching.
Since Mr Architecture 2.9, all caches used by Mr Architecture (including some internal metadata caches not discussed in this document) are of one of two types:
As a general rule, ConcurrentReaderHashMaps are used for bean type metadata, which is not changing very often. ConcurrentHashMaps are used to implement the LRU caches, because these are constantly changing in response to user requests.
The effect of this is that, in an environment capable of parallel processing, Mr Architecture will be able to scale to use all available processing units. There may be application or application server limitations which prevent this ideal, but it should be possible under the right conditions.
Therefore, an additional way, as an application deployer, you can shoot yourself in the foot is to somehow restrict an application from using two or more processing units at a time, as this is the primary way server latency can be decreased under high load conditions: by allowing user transactions to be processed concurrently without the loss of performance through context switching when limited to one processing unit.
Since Mr Architecture 3.0, a new ServerContainer implementation has become available. This container, the LightweightContainer, reimplements key methods in the ServerContainer so that it no longer holds commands in memory in preparation for the batch execution of transactions at commit time. Provided application processes do not need to see the results of their transactions, this can provide an improvement in time and space efficiency. However, this container opens more database transactions and keeps them open for longer periods. Also, applications which rely on the intrinsic undocumented semantics of the ServerContainer database access method may have functional issues.
Refinements to the ServerContainer itself in Mr Architecture 3.0 also allow earlier garbage collection of objects participating in long-lived transactions, which may allow larger transactions and increase server throughput during such transactions by allowing the garbage collector to work less. It can also, of course, can be used to reduce the server footprint further. (Hence its name.)
Refer to the LightweightContainer API documentation for instructions on using the LightweightContainer in your applications.
[1] A JIT VM like HotSpot has additional requirements for keeping compiled copies of Java methods. Some VM and operating system configurations may also carry a significant per thread overhead in the heap, but this can depend on whether thread data structures are allocated from the VM heap or elsewhere.
[2] Where transactions are particularly large (say greater than 128 commands,) the size of internalized log caches may also become significant--estimate this requirement based on the worst case log file fragment size per maximal transaction multipled by the worst case concurrent user count.
[3] In systems with a particularly large session load, the size of the objects used to keep session information may also need to be taken into account--estimate this requirement based on the maximal user count multiplied by a factor of 100 kB.
[4] In practice, cache effects lag slightly after database commission to avoid a race condition where the cache contains data which may not commit due to an error. For example, if data in a transaction which is subsequently rolled-back polluted the cache long enough for an intervening transaction to pick up the wrong data, there would be doubt as to which data that transaction may obtain.